
The field of pathology is undergoing a transformation through digital and computational advances like large-scale slide digitization and AI-based image analysis powered by the rise of pathology foundation models. Last year we announced our collaboration with Mayo Clinic – our co-developed pathology foundation model Atlas that demonstrated leading performance across a wide range of clinical applications. Despite the clear utility of pathology foundation models in research, bringing them into everyday clinical use has remained a broader challenge. This is because pathology foundation models generally require significant computational resources and must work reliably across diverse clinical settings1.
This year we're excited to announce Atlas 2, our new foundation model that pushes the boundaries of performance and robustness in digital pathology and has taken the lead as the top performing pathology foundation model to date. Atlas 2 was trained on a large pathology dataset of 5.5 million whole slide images from three major institutions – Mayo Clinic, LMU Munich and Charité – Universitätsmedizin Berlin – and consists of approximately 2 billion parameters. To reduce computational demand, we also distilled Atlas 2 into two lightweight, resource-efficient versions - Atlas 2-B and Atlas 2-S - which preserve much of the high performance of Atlas 2 but require significantly less computing power.
In this overview, we discuss results from our comprehensive evaluation across 80 public benchmarks and five evaluation frameworks that demonstrate Atlas 2's performance, robustness, and efficiency.
Taking the Lead as the Top Performing Foundation Model
To ensure reproducibility and comparability, we evaluated Atlas 2 against 15 publicly available foundation models across five established frameworks: HEST, eva, PathoROB, Plismbench, and Patho-Bench. Atlas 2-B and Atlas 2-S were additionally compared against five models of similar sizes.
On average, when evaluated across a total of 80 benchmarks, Atlas 2 outperformed all other public foundation models. Specifically, Atlas 2 led on all benchmark suites: HEST, which measures performance on molecular tasks; EVA, which focuses on morphological tasks; and PathoROB and Plismbench, which assess the robustness of foundation models. This high performance stems from a combination of the extensive, high-quality data set, careful data curation, and our unique algorithmic innovations.
Among resource-efficient models, Atlas 2-B and Atlas 2-S also demonstrate best-in-class average performance, with Atlas 2-B matching or exceeding larger models such as Atlas, UNI2-H, and H-Optimus-0.
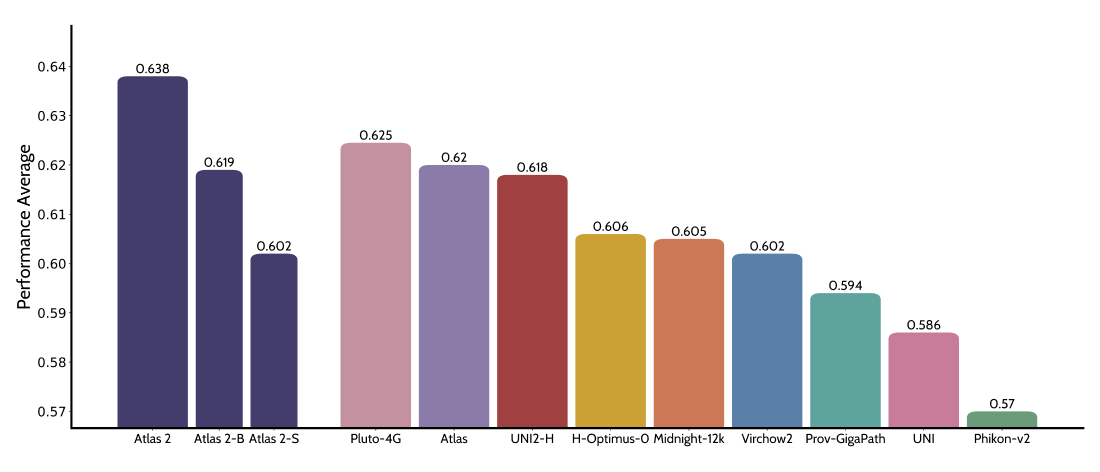
Establishing a Foundation of Robustness for Real-World Deployment
High performance is essential, but robustness is where many foundation models still struggle. Different scanners and lab processing techniques result in substantial differences in visual appearance which can lead to performance drops in real world conditions. Therefore, robustness is crucial for deploying foundation models in clinical settings. One key to a robust model was expanding our training database and increasing the model parameter count, which allowed us to specifically seek out and incorporate a diversity of diseases, staining types, and scanners during training.
To evaluate robustness, we tested the models on two novel robustness benchmarks designed to assess performance against medical center variations (PathoROB) and scanning and staining variations (Plismbench) - two of the most crucial challenges for clinical AI deployment. Atlas 2, Atlas 2-B, and Atlas 2-S all demonstrated the highest average robustness compared to other foundation models. This strong robustness indicates that Atlas 2 is well suited for application in clinical settings.
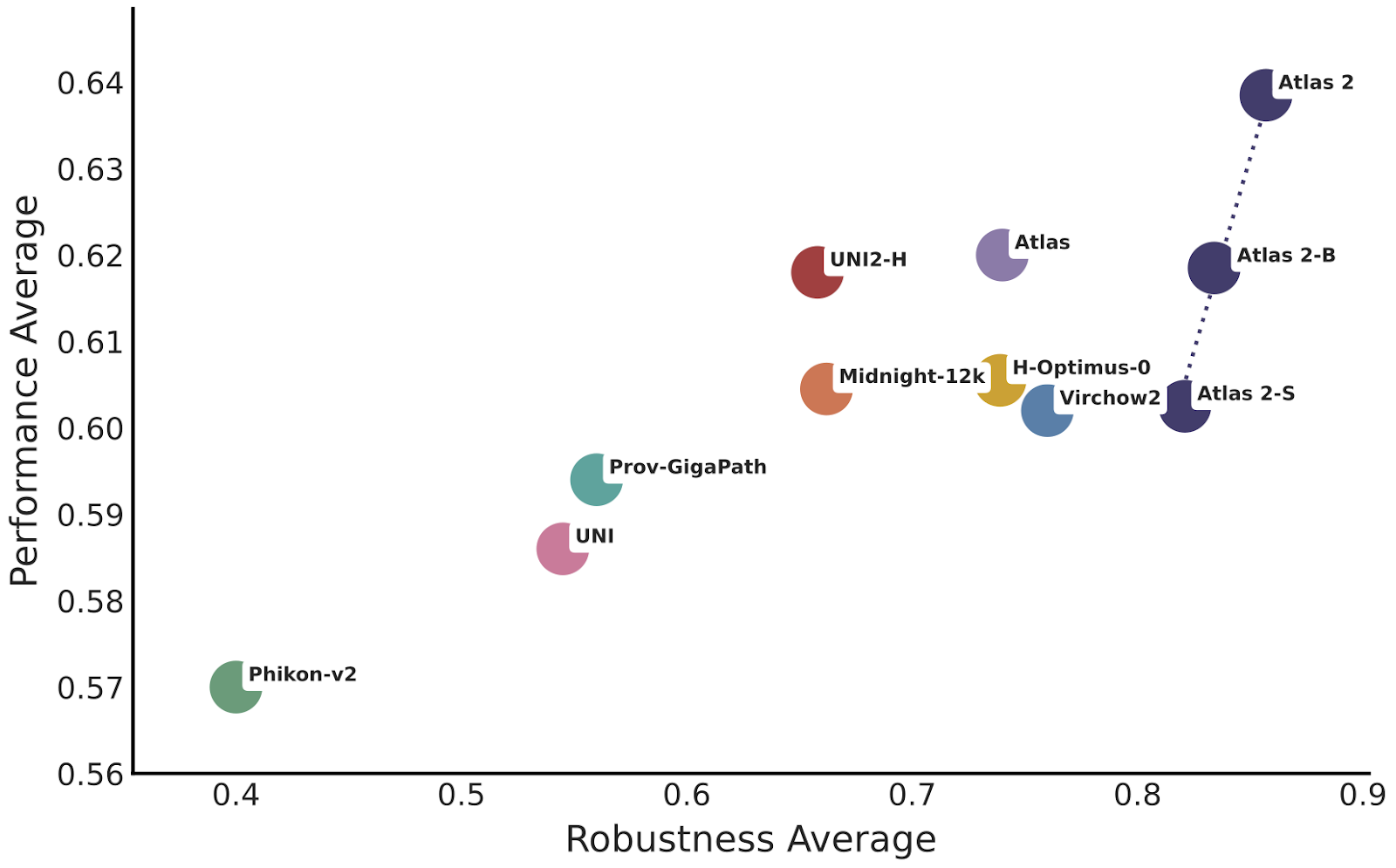
Efficiency: Faster Inference With Competitive Performance
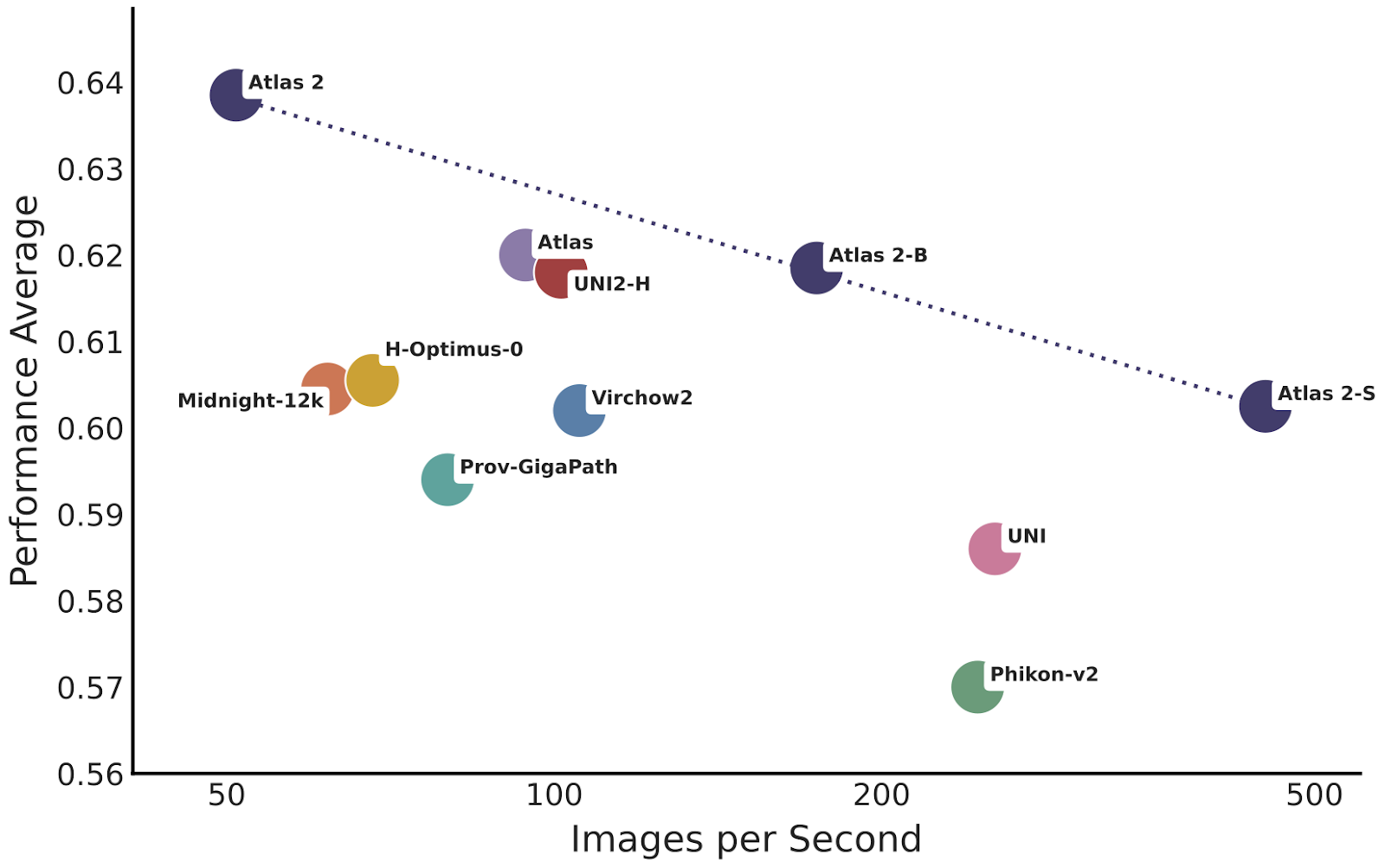
Foundation models that achieve better performance or robustness typically require more computational resources to run. If these models slow down slide processing times in pathology workflows, they may have limited practical value despite their technical improvements. To address this challenge, we built three models to fit different deployment scenarios:
- Atlas 2: 2B parameters, state-of-the-art performance across all performance benchmarks
- Atlas 2-B: 24x smaller in parameter size, 3.4x more resource efficient
- Atlas 2-S: 91x smaller in parameter size, 9x more resource efficient
Atlas 2-B demonstrates a strong efficiency-performance balance, outperforming much larger models including Atlas, UNI2-H, H-Optimus-0, and Virchow2 despite being significantly more efficient. Atlas 2-S achieves the highest efficiency and processing speed compared to both larger foundation models and similarly-sized alternatives.
Looking Ahead
Atlas 2 represents a significant milestone, setting new standards for performance, robustness, and efficiency in digital pathology. We have begun integrating our models into different applications, including Atlas H&E-TME, our tool for AI-powered tumor microenvironment analysis in H&E slides. The models enable efficient, widespread adoption of AI in real-world clinical environments for tasks such as mutation prediction, TME characterization, and treatment response prediction. Atlas 2 also includes clinical-grade regulatory documentation to ensure smooth integration into clinical devices.
For detailed methodology and full results, the complete paper is available at https://arxiv.org/pdf/2601.05148.
Authors
Written by Lisa Zheng, Marketing Lead at Aignostics, and Lukas Muttenthaler, Timo Milbich, Jonas Dippel and Stephan Tietz on behalf of the Foundation Model Team at Aignostics.
Citations
- Kömen, J., de Jong, E.D., Hense, J, et al. (2025). "Towards Robust Foundation Models for Digital Pathology." arXiv:2507.17845 [eess.IV]